【mysql】创建索引时如何考虑order by查询
时间:2015-12-27 04:12:32 作者:beebol 标签: mysql order by 分类: mysql
给表加索引时,其中一些查询会用到order by ,group by之类的,在低版本(有ICP之前版本)中可能会遇到一种情况,where查询用到索引,那么order by就无法用到索引,当然我们可以创建联合索引,那么什么情况下创建联合索引是有效的呢?可以通过explain 看order by是否有file sort,where是否使用到了索引。
那么order by 如何避免file sort,之后的索引应该如何创建,在这里做下总结:1、根据索引查询数据后,是否还需要排序,如果需要就会产生file sort,否则不会;所以在创建索引的时候需要特别注意,能将避免file sort的尽可能通过创建索引来解决,无法解决的就改sql,或者考虑其它办法。但需要考虑file sort不一定会慢,主要还得看数据量,有些情况还是允许file sort的,file sort也分为内存和磁盘,只有在sort buffer装载不下的情况,才能会磁盘中去进行分块排序。
2、联合索引使用长度需要注意,看联合索引用到了几列,什么样了sql会用到索引的程度。如,a为范围查询,<、>、!=,那么b就无法使用到(不支持ICP情况)。只能当前缀列为= 、<=或者>=时,后面的列才会用到。
如下是联合索引idx_a_b_c(a,b,c)各种查询条件下是否有file sort,另外使用到的索引情况。(mysql版本,5.1.63)
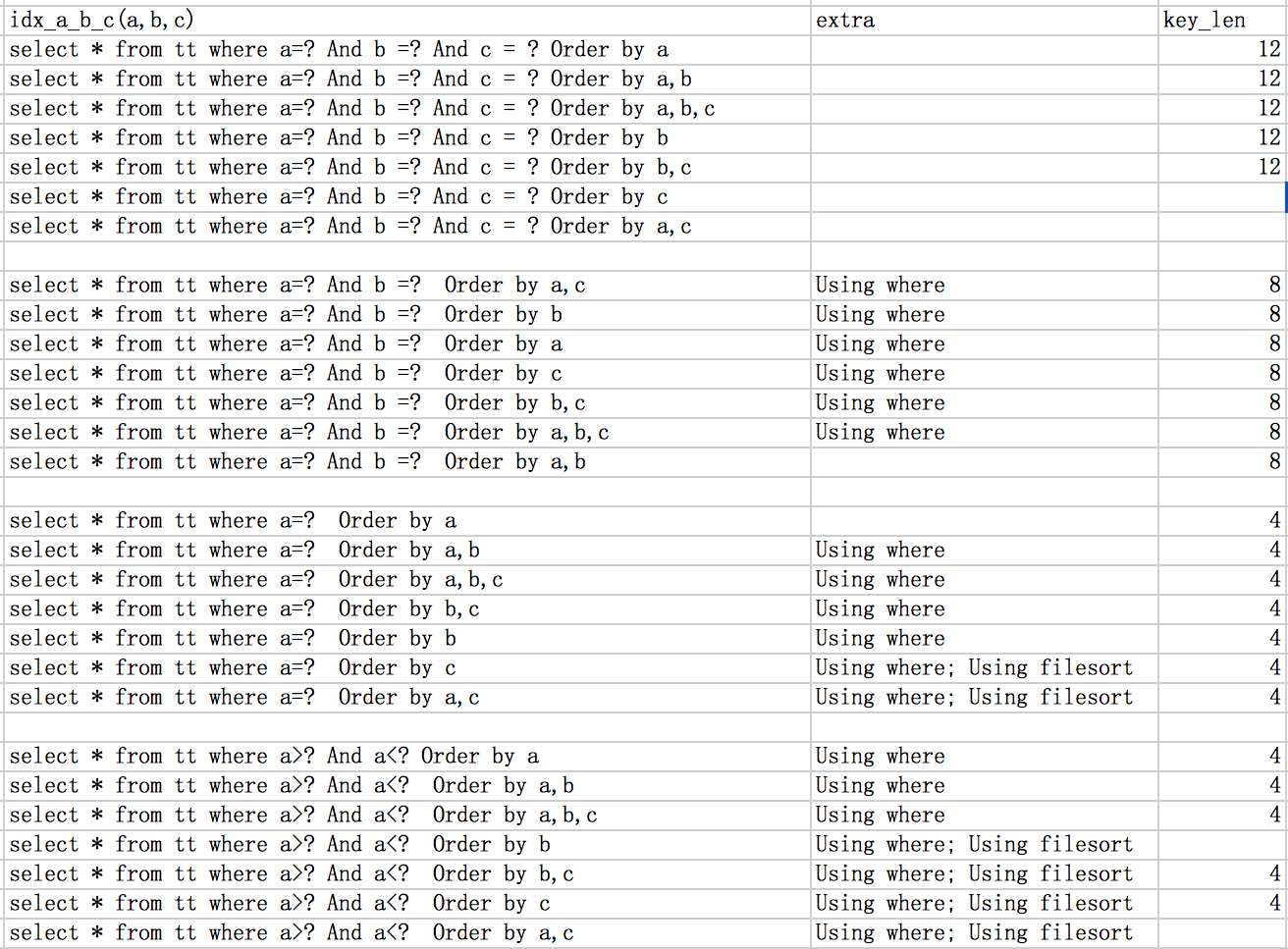
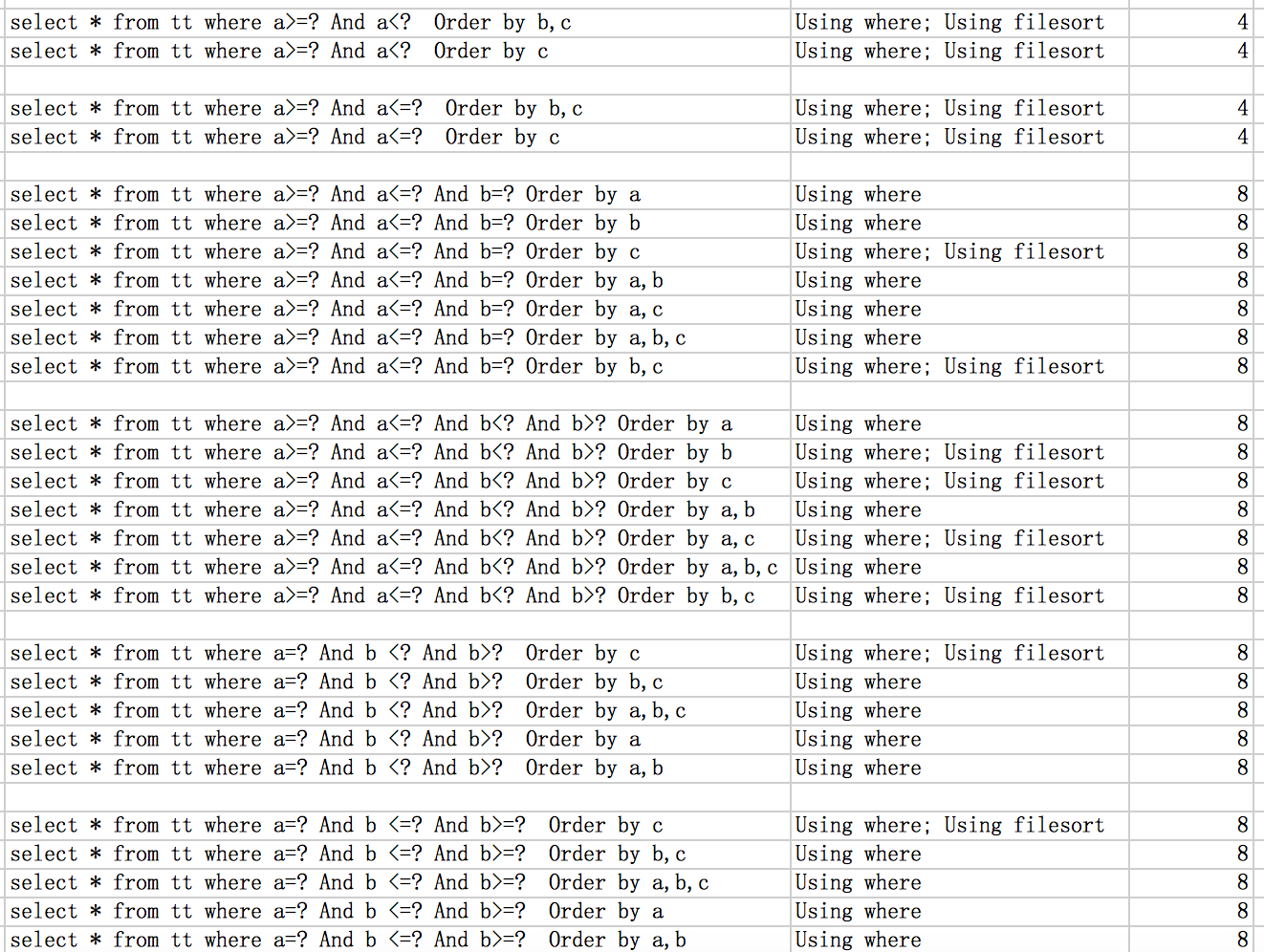
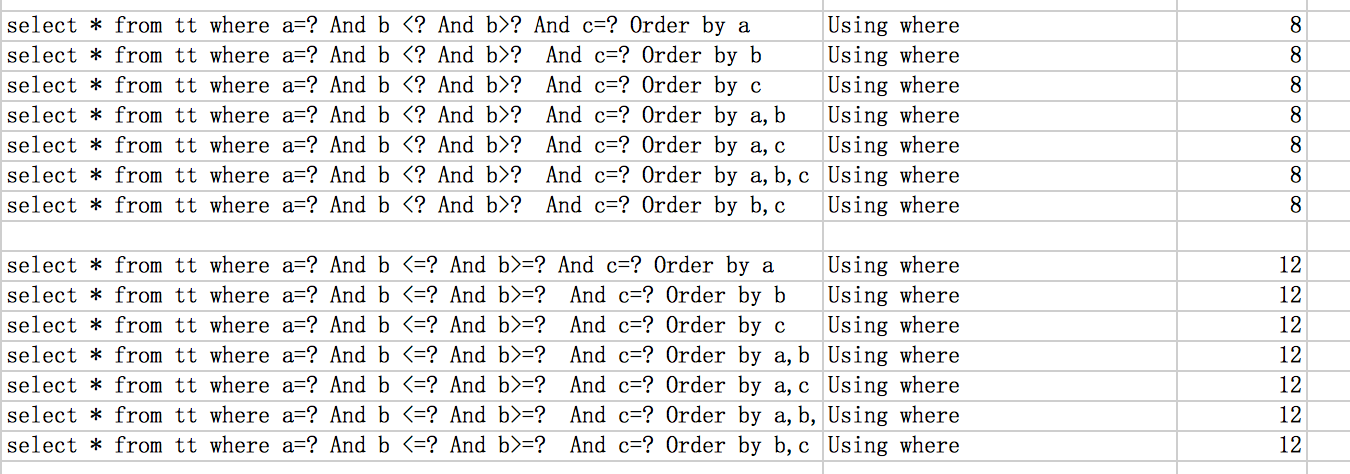
思考:
create table ttt (
id int(10) NOT NULL AUTO_INCREMENT,
uid int(10) NOT NULL,
status tinyint(2) NOT NULL,
ordertime int(11) NOT NULL,
view varchar(20) NOT NULL
primary key(id),
key idx_status_rodertime(status,ordertime),
key idx_uid(uid))engine = innodb;
)engine = innodb;
此表有3000多w.其中uid和status,ordertime的distinct值。
mysql> select count(distinct uid) from ttt; +------------------------+ | count(distinct uid) | +------------------------+ | 9112 | +------------------------+ 1 row in set (51.89 sec) mysql> select count(distinct status,ordertime) from ttt; +--------------------------------+ | count(distinct status,ordertime) | +--------------------------------+ | 5424 | +--------------------------------+1 row in set (51.77 sec) 1 row in set (51.77 sec)
上表有这样的一个查询 :
select * from ttt where status=6 and ordertime >=1451012466 and ordertime <=1451016066 order by uid asc limit 100;
在目前这种情况下,如何优化这条sql,为什么?(数据库版本不限)
参考:http://imysql.com/2014/09/19/mysql-faq-is-composite-index-support-different-sort-order.shtml